At 8:59 AM on a Monday, one of our finance jobs looked healthy: schedule was green, Lambda had no obvious errors, and CloudWatch showed “successful” invocations. By 9:17 AM, support tickets started: some customers received duplicate invoices, while others received none. The root cause was not dramatic. A retry happened after a transient timeout, and our job logic was not idempotent enough for a scheduled system that delivers events at least once.
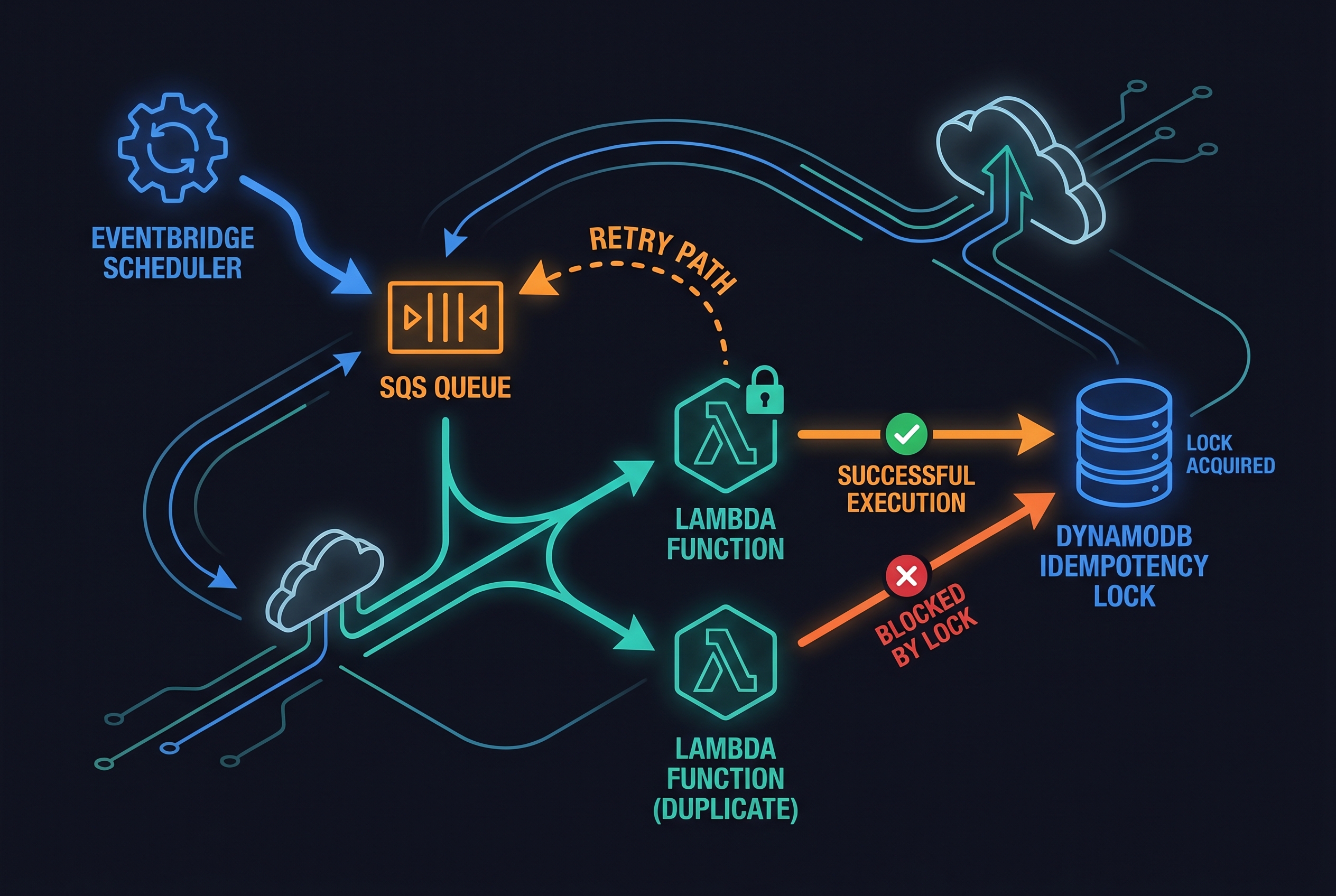
That incident changed how I design any recurring backend task. If your architecture relies on cron-like automation in AWS, the safest pattern I’ve found is this: EventBridge Scheduler + SQS + idempotent consumers, with clear retry and dead-letter boundaries. This is the core of an AWS idempotent scheduler setup that survives transient failures without creating duplicate side effects.
In this guide, I’ll show the pattern, where it can bite you, and how to make tradeoffs explicit before production teaches you the hard way. You can implement this incrementally without rewriting your whole stack.
The subtle failure mode most teams underestimate
A lot of teams treat scheduled jobs as “single fire” workflows. But AWS primitives do not promise that behavior end to end:
- EventBridge Scheduler provides at-least-once delivery and configurable retries.
- Lambda with SQS event source mapping can also process a message more than once unless your handler is idempotent.
- SQS FIFO deduplication helps reduce duplicate sends, but it is not a complete business-level exactly-once guarantee.
So the practical question is not “how do I avoid retries?” It is “how do I make retries safe?” If you already liked our post on deadline propagation and graceful degradation, this is the scheduling counterpart of that same reliability mindset.
The production pattern: schedule -> queue -> idempotent worker
Here’s the architecture I recommend for most recurring jobs:
- EventBridge Scheduler triggers on cron/rate and sends a message to SQS.
- The message carries a deterministic execution key (for example,
billing-close#2026-04-26). - Lambda polls SQS, attempts to atomically claim the key in DynamoDB, and only one invocation performs side effects.
- Failures are retried with controlled policy, and non-recoverable issues land in a DLQ for investigation.
For ordering-sensitive jobs, use FIFO queues and a deliberate MessageGroupId. For high-throughput independent jobs, use multiple groups (or standard queues with stronger app-level idempotency controls).
# Terraform: Scheduler -> SQS FIFO (work queue) + standard DLQ for Scheduler
resource "aws_sqs_queue" "work_fifo" {
name = "billing-reconcile.fifo"
fifo_queue = true
content_based_deduplication = false
visibility_timeout_seconds = 180
}
resource "aws_sqs_queue" "scheduler_dlq" {
name = "billing-scheduler-dlq"
}
resource "aws_iam_role" "scheduler_exec" {
name = "eventbridge-scheduler-exec"
assume_role_policy = jsonencode({
Version = "2012-10-17",
Statement = [{
Effect = "Allow",
Principal = { Service = "scheduler.amazonaws.com" },
Action = "sts:AssumeRole"
}]
})
}
resource "aws_iam_role_policy" "scheduler_send_sqs" {
role = aws_iam_role.scheduler_exec.id
policy = jsonencode({
Version = "2012-10-17",
Statement = [{
Effect = "Allow",
Action = ["sqs:SendMessage"],
Resource = aws_sqs_queue.work_fifo.arn
}]
})
}
resource "aws_scheduler_schedule" "daily_billing_close" {
name = "daily-billing-close"
schedule_expression = "cron(30 3 * * ? *)" # 03:30 UTC daily
flexible_time_window {
mode = "OFF"
}
target {
arn = "arn:aws:scheduler:::aws-sdk:sqs:sendMessage"
role_arn = aws_iam_role.scheduler_exec.arn
input = jsonencode({
QueueUrl = aws_sqs_queue.work_fifo.url
MessageBody = jsonencode({ job_name = "billing-close", scheduled_time = "<aws.scheduler.scheduled-time>" })
MessageGroupId = "billing-close"
MessageDeduplicationId = "billing-close#<aws.scheduler.scheduled-time>"
})
retry_policy {
maximum_event_age_in_seconds = 3600
maximum_retry_attempts = 8
}
dead_letter_config {
arn = aws_sqs_queue.scheduler_dlq.arn
}
}
}Idempotency where it counts: the business operation
Queue-level dedup helps, but the real safety boundary is your side-effect function: “charge card,” “issue invoice,” “send payout,” “publish report.” I prefer an atomic claim in DynamoDB so duplicates become harmless no-ops.
import json
import os
import time
import boto3
from botocore.exceptions import ClientError
dynamodb = boto3.resource("dynamodb")
locks = dynamodb.Table(os.environ["IDEMPOTENCY_TABLE"])
def claim_once(key: str, ttl_seconds: int = 86400) -> bool:
now = int(time.time())
expires = now + ttl_seconds
try:
locks.put_item(
Item={"idempotency_key": key, "created_at": now, "expiration": expires},
ConditionExpression="attribute_not_exists(idempotency_key)",
)
return True
except ClientError as e:
if e.response["Error"]["Code"] == "ConditionalCheckFailedException":
return False
raise
def run_billing_close(payload: dict) -> None:
# do side effects here (DB writes, external API calls, etc.)
pass
def handler(event, context):
failures = []
for record in event["Records"]:
try:
body = json.loads(record["body"])
scheduled_time = body["scheduled_time"][:10] # yyyy-mm-dd
idem_key = f"{body['job_name']}#{scheduled_time}"
if not claim_once(idem_key):
# Duplicate delivery, safe to ignore
continue
run_billing_close(body)
except Exception:
failures.append({"itemIdentifier": record["messageId"]})
# Partial batch response prevents reprocessing successful messages
return {"batchItemFailures": failures}This design is intentionally boring, and that is exactly what you want in scheduled automation.
Tradeoffs you should decide up front
1) FIFO ordering vs throughput
Single message group gives clean ordering but caps parallelism. If jobs are independent, partition by tenant/region/job type.
2) Long retry windows vs operational noise
Large retry windows improve eventual success but can hide persistent config bugs for longer. Keep a DLQ and alerting from day one.
3) “Exactly once” language vs reality
In distributed systems, “exactly once” is usually an application-level effect, not a transport guarantee. Be explicit with your team: we aim for effectively once business outcomes.
If this resonates, it pairs well with our article on ETag and idempotency keys in mobile sync and our state-machine reliability blueprint here.
The observability contract that prevents “green but broken” incidents
The biggest mistake I still see is teams monitoring only infrastructure health. Scheduler can look healthy while your business flow silently fails. For an idempotent schedule, I now insist on three metric layers:
- Trigger metrics: schedule invocations, retry attempts, and DLQ count.
- Transport metrics: queue depth, oldest message age, Lambda error/timeout rate.
- Business metrics: completed reports, invoices issued, rows reconciled, or whatever outcome actually matters.
Then add one daily reconciliation check. Example: if your billing-close job should create one ledger snapshot per day, run a cheap verifier at +30 minutes and alert if today’s snapshot is missing or duplicated. This single check catches most quiet failures faster than log diving.
For retries, avoid synchronized storms. Use bounded retries and jitter where client-side retries exist, so the platform and your own code do not amplify each other. AWS has written extensively about this pattern in their Builder’s Library, and it applies directly to scheduled pipelines.
Finally, make your runbook answer three concrete questions in under five minutes:
- Did the schedule fire?
- Was the message consumed exactly once at business level?
- If not, where is the failed payload and who owns the fix?
That discipline turns “we think it ran” into “we can prove what happened.”
Troubleshooting: when the schedule still behaves weirdly
Symptom: job runs twice for the same day
- Check if idempotency key includes deterministic date/window and not runtime UUID.
- Verify DynamoDB conditional write is actually enforced (look for
ConditionalCheckFailedExceptionon duplicates). - Confirm SQS visibility timeout exceeds your realistic processing time.
Symptom: messages keep reappearing in queue
- Ensure Lambda returns partial batch failures correctly.
- Inspect function timeout vs job duration. If timeout is shorter, retries are guaranteed.
- Validate downstream API retry behavior to avoid compounded retry storms.
Symptom: Scheduler says “success,” but business output missing
- Remember Scheduler only confirms target invocation path, not your domain completion.
- Track a domain completion metric (for example, “invoices generated count”).
- Read DLQ payload attributes such as error code, retry attempts, and exhausted retry condition.
Also review our ECS rollback runbook if your workers are containerized on Fargate: ECS/Fargate deployment recovery playbook.
FAQ
1) Should I always use FIFO for scheduled jobs?
No. Use FIFO when ordering and duplicate-send reduction matter. For very high fan-out independent tasks, standard queues plus strong app-level idempotency can be simpler and cheaper.
2) Is queue deduplication enough without DynamoDB locks?
Usually no. FIFO deduplication window is finite, and retries can happen across layers. Protect the side-effect operation itself with an idempotency key store.
3) Can I skip a DLQ if retries are configured?
I would not. Retries solve transient failures; DLQ helps you debug persistent ones. Without DLQ, you lose forensic visibility exactly when you need it most.
Actionable takeaways
- Model scheduled delivery as at-least-once, then design idempotent side effects first.
- Use deterministic execution keys (business date/window), not random run IDs.
- Combine Scheduler retry policy with DLQ, and alert on DLQ depth immediately.
- Use partial batch failure responses for Lambda + SQS to avoid replaying successes.
- Document tradeoffs (ordering, throughput, latency, cost) before launch, not after incident review.
Leave a Reply